February, 2016
2016-02-05
- Looking at some DAGRIS data for Abenet Yabowork
- Lots of issues with spaces, newlines, etc causing the import to fail
- I noticed we have a very interesting list of countries on CGSpace:
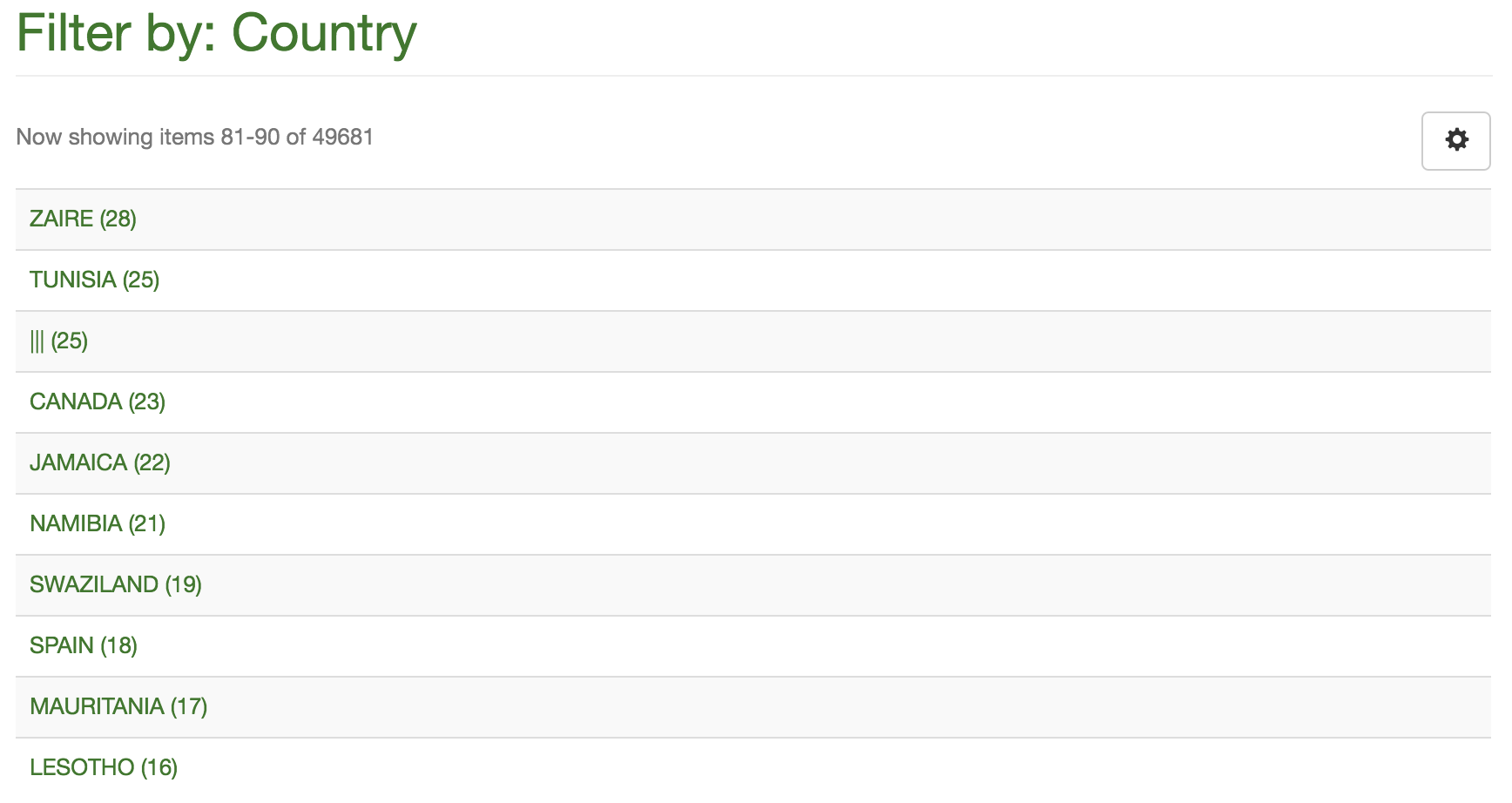
- Not only are there 49,000 countries, we have some blanks (25)…
- Also, lots of things like “COTE D`LVOIRE” and “COTE D IVOIRE”
2016-02-06
- Found a way to get items with null/empty metadata values from SQL
- First, find the
metadata_field_idfor the field you want from themetadatafieldregistrytable:
dspacetest=# select * from metadatafieldregistry;
- In this case our country field is 78
- Now find all resources with type 2 (item) that have null/empty values for that field:
dspacetest=# select resource_id from metadatavalue where resource_type_id=2 and metadata_field_id=78 and (text_value='' OR text_value IS NULL);
- Then you can find the handle that owns it from its
resource_id:
dspacetest=# select handle from item, handle where handle.resource_id = item.item_id AND item.item_id = '22678';
- It’s 25 items so editing in the web UI is annoying, let’s try SQL!
dspacetest=# delete from metadatavalue where metadata_field_id=78 and text_value='';
DELETE 25
- After that perhaps a regular
dspace index-discovery(no -b) should suffice… - Hmm, I indexed, cleared the Cocoon cache, and restarted Tomcat but the 25 “|||” countries are still there
- Maybe I need to do a full re-index…
- Yep! The full re-index seems to work.
- Process the empty countries on CGSpace
2016-02-07
- Working on cleaning up Abenet’s DAGRIS data with OpenRefine
- I discovered two really nice functions in OpenRefine:
value.trim()andvalue.escape("javascript")which shows whitespace characters like\r\n! - For some reason when you import an Excel file into OpenRefine it exports dates like 1949 to 1949.0 in the CSV
- I re-import the resulting CSV and run a GREL on the date issued column:
value.replace("\.0", "") - I need to start running DSpace in Mac OS X instead of a Linux VM
- Install PostgreSQL from homebrew, then configure and import CGSpace database dump:
$ postgres -D /opt/brew/var/postgres
$ createuser --superuser postgres
$ createuser --pwprompt dspacetest
$ createdb -O dspacetest --encoding=UNICODE dspacetest
$ psql postgres
postgres=# alter user dspacetest createuser;
postgres=# \q
$ pg_restore -O -U dspacetest -d dspacetest ~/Downloads/cgspace_2016-02-07.backup
$ psql postgres
postgres=# alter user dspacetest nocreateuser;
postgres=# \q
$ vacuumdb dspacetest
$ psql -U dspacetest -f ~/src/git/DSpace/dspace/etc/postgres/update-sequences.sql dspacetest -h localhost
- After building and running a
fresh_installI symlinked the webapps into Tomcat’s webapps folder:
$ mv /opt/brew/Cellar/tomcat/8.0.30/libexec/webapps/ROOT /opt/brew/Cellar/tomcat/8.0.30/libexec/webapps/ROOT.orig
$ ln -sfv ~/dspace/webapps/xmlui /opt/brew/Cellar/tomcat/8.0.30/libexec/webapps/ROOT
$ ln -sfv ~/dspace/webapps/rest /opt/brew/Cellar/tomcat/8.0.30/libexec/webapps/rest
$ ln -sfv ~/dspace/webapps/jspui /opt/brew/Cellar/tomcat/8.0.30/libexec/webapps/jspui
$ ln -sfv ~/dspace/webapps/oai /opt/brew/Cellar/tomcat/8.0.30/libexec/webapps/oai
$ ln -sfv ~/dspace/webapps/solr /opt/brew/Cellar/tomcat/8.0.30/libexec/webapps/solr
$ /opt/brew/Cellar/tomcat/8.0.30/bin/catalina start
- Add CATALINA_OPTS in
/opt/brew/Cellar/tomcat/8.0.30/libexec/bin/setenv.sh, as this script is sourced by thecatalinastartup script - For example:
CATALINA_OPTS="-Djava.awt.headless=true -Xms2048m -Xmx2048m -XX:MaxPermSize=256m -XX:+UseConcMarkSweepGC -Dfile.encoding=UTF-8"
- After verifying that the site is working, start a full index:
$ ~/dspace/bin/dspace index-discovery -b
2016-02-08
- Finish cleaning up and importing ~400 DAGRIS items into CGSpace
- Whip up some quick CSS to make the button in the submission workflow use the XMLUI theme’s brand colors (#154)
2016-02-09
- Re-sync DSpace Test with CGSpace
- Help Sisay with OpenRefine
- Enable HTTPS on DSpace Test using Let’s Encrypt:
$ cd ~/src/git
$ git clone https://github.com/letsencrypt/letsencrypt
$ cd letsencrypt
$ sudo service nginx stop
# add port 443 to firewall rules
$ ./letsencrypt-auto certonly --standalone -d dspacetest.cgiar.org
$ sudo service nginx start
$ ansible-playbook dspace.yml -l linode02 -t nginx,firewall -u aorth --ask-become-pass
- We should install it in /opt/letsencrypt and then script the renewal script, but first we have to wire up some variables and template stuff based on the script here: https://letsencrypt.org/howitworks/
- I had to export some CIAT items that were being cleaned up on the test server and I noticed their
dc.contributor.authorfields have DSpace 5 authority index UUIDs… - To clean those up in OpenRefine I used this GREL expression:
value.replace(/::\w{8}-\w{4}-\w{4}-\w{4}-\w{12}::600/,"") - Getting more and more hangs on DSpace Test, seemingly random but also during CSV import
- Logs don’t always show anything right when it fails, but eventually one of these appears:
org.dspace.discovery.SearchServiceException: Error while processing facet fields: java.lang.OutOfMemoryError: Java heap space
- or
Caused by: java.util.NoSuchElementException: Timeout waiting for idle object
- Right now DSpace Test’s Tomcat heap is set to 1536m and we have quite a bit of free RAM:
# free -m
total used free shared buffers cached
Mem: 3950 3902 48 9 37 1311
-/+ buffers/cache: 2552 1397
Swap: 255 57 198
- So I’ll bump up the Tomcat heap to 2048 (CGSpace production server is using 3GB)
2016-02-11
- Massaging some CIAT data in OpenRefine
- There are 1200 records that have PDFs, and will need to be imported into CGSpace
- I created a
filenamecolumn based on thedc.identifier.urlcolumn using the following transform:
value.split('/')[-1]
- Then I wrote a tool called
generate-thumbnails.pyto download the PDFs and generate thumbnails for them, for example:
$ ./generate-thumbnails.py ciat-reports.csv
Processing 64661.pdf
> Downloading 64661.pdf
> Creating thumbnail for 64661.pdf
Processing 64195.pdf
> Downloading 64195.pdf
> Creating thumbnail for 64195.pdf
2016-02-12
- Looking at CIAT’s records again, there are some problems with a dozen or so files (out of 1200)
- A few items are using the same exact PDF
- A few items are using HTM or DOC files
- A few items link to PDFs on IFPRI’s e-Library or Research Gate
- A few items have no item
- Also, I’m not sure if we import these items, will be remove the
dc.identifier.urlfield from the records?
2016-02-12
- Looking at CIAT’s records again, there are some files linking to PDFs on Slide Share, Embrapa, UEA UK, and Condesan, so I’m not sure if we can use those
- 265 items have dirty, URL-encoded filenames:
$ ls | grep -c -E "%"
265
- I suggest that we import ~850 or so of the clean ones first, then do the rest after I can find a clean/reliable way to decode the filenames
- This python2 snippet seems to work in the CLI, but not so well in OpenRefine:
$ python -c "import urllib, sys; print urllib.unquote(sys.argv[1])" CIAT_COLOMBIA_000169_T%C3%A9cnicas_para_el_aislamiento_y_cultivo_de_protoplastos_de_yuca.pdf
CIAT_COLOMBIA_000169_Técnicas_para_el_aislamiento_y_cultivo_de_protoplastos_de_yuca.pdf
- Merge pull requests for submission form theming (#178) and missing center subjects in XMLUI item views (#176)
- They will be deployed on CGSpace the next time I re-deploy
2016-02-16
- Turns out OpenRefine has an unescape function!
value.unescape("url")
- This turns the URLs into human-readable versions that we can use as proper filenames
- Run web server and system updates on DSpace Test and reboot
- To merge
dc.identifier.urlanddc.identifier.url[], rename the second column so it doesn’t have the brackets, likedc.identifier.url2 - Then you create a facet for blank values on each column, show the rows that have values for one and not the other, then transform each independently to have the contents of the other, with “||” in between
- Work on Python script for parsing and downloading PDF records from
dc.identifier.url - To turn
dc.identifier.urlinto filenames, create a new column based o - To get filenames from
dc.identifier.url, create a new column based on this transform:forEach(value.split('||'), v, v.split('/')[-1]).join('||') - This also works for records that have multiple URLs (separated by “||”)
2016-02-17
- Re-deploy CGSpace, run all system updates, and reboot
- More work on CIAT data, cleaning and doing a last metadata-only import into DSpace Test
- SAFBuilder has a bug preventing it from processing filenames containing more than one underscore
- Need to re-process the filename column to replace multiple underscores with one:
value.replace(/_{2,}/, "_")
2016-02-20
- Turns out the “bug” in SAFBuilder isn’t a bug, it’s a feature that allows you to encode extra information like the destintion bundle in the filename
- Also, it seems DSpace’s SAF import tool doesn’t like importing filenames that have accents in them:
java.io.FileNotFoundException: /usr/share/tomcat7/SimpleArchiveFormat/item_1021/CIAT_COLOMBIA_000075_Medición_de_palatabilidad_en_forrajes.pdf (No such file or directory)
- Need to rename files to have no accents or umlauts, etc…
- Useful custom text facet for URLs ending with “.pdf”:
value.endsWith(".pdf")
2016-02-22
- To change Spanish accents to ASCII in OpenRefine:
value.replace('ó','o').replace('í','i').replace('á','a').replace('é','e').replace('ñ','n')
- But actually, the accents might not be an issue, as I can successfully import files containing Spanish accents on my Mac
- On closer inspection, I can import files with the following names on Linux (DSpace Test):
Bitstream: tést.pdf
Bitstream: tést señora.pdf
Bitstream: tést señora alimentación.pdf
- Seems it could be something with the HFS+ filesystem actually, as it’s not UTF-8 (it’s something like UCS-2)
- HFS+ stores filenames as a string, and filenames with accents get stored as character+accent whereas Linux’s ext4 stores them as an array of bytes
- Running the SAFBuilder on Mac OS X works if you’re going to import the resulting bundle on Mac OS X, but if your DSpace is running on Linux you need to run the SAFBuilder there where the filesystem’s encoding matches
2016-02-29
- Got notified by some CIFOR colleagues that the Google Scholar team had contacted them about CGSpace’s incorrect ordering of authors in Google Scholar metadata
- Turns out there is a patch, and it was merged in DSpace 5.4: https://jira.duraspace.org/browse/DS-2679
- I’ve merged it into our
5_x-prodbranch that is currently based on DSpace 5.1 - We found a bug when a user searches from the homepage, sorts the results, and then tries to click “View More” in a sidebar facet
- I am not sure what causes it yet, but I opened an issue for it: https://github.com/ilri/DSpace/issues/179
- Have more problems with SAFBuilder on Mac OS X
- Now it doesn’t recognize description hints in the filename column, like:
test.pdf__description:Blah - But on Linux it works fine
- Trying to test Atmire’s series of stats and CUA fixes from January and February, but their branch history is really messy and it’s hard to see what’s going on
- Rebasing their branch on top of our production branch results in a broken Tomcat, so I’m going to tell them to fix their history and make a proper pull request